In my last posts I’ve build a head version model starting from a SDDM relational model. In this post I’m going to create an Anchor model from a SDDM logical model. I think this is a better approach, it is a more domain driven approach.
I’ve created a small (meta) data model to store table information in a model. The Model entity and the Table entity both store the name of a model/table. But instead of using a name attribute I made an extra entity Term. It stores all the ’terms’ we’re going to use. This Term entity has the attribute name. Later we can extend the Term entity with abbreviations or mnemonics of a name. Think of the 2 or 3 character mnemonics used in Anchor modeling or the abbreviations often used when deploying stuff to Oracle because of the 30 character limit. The name is an unique identifier of a Term
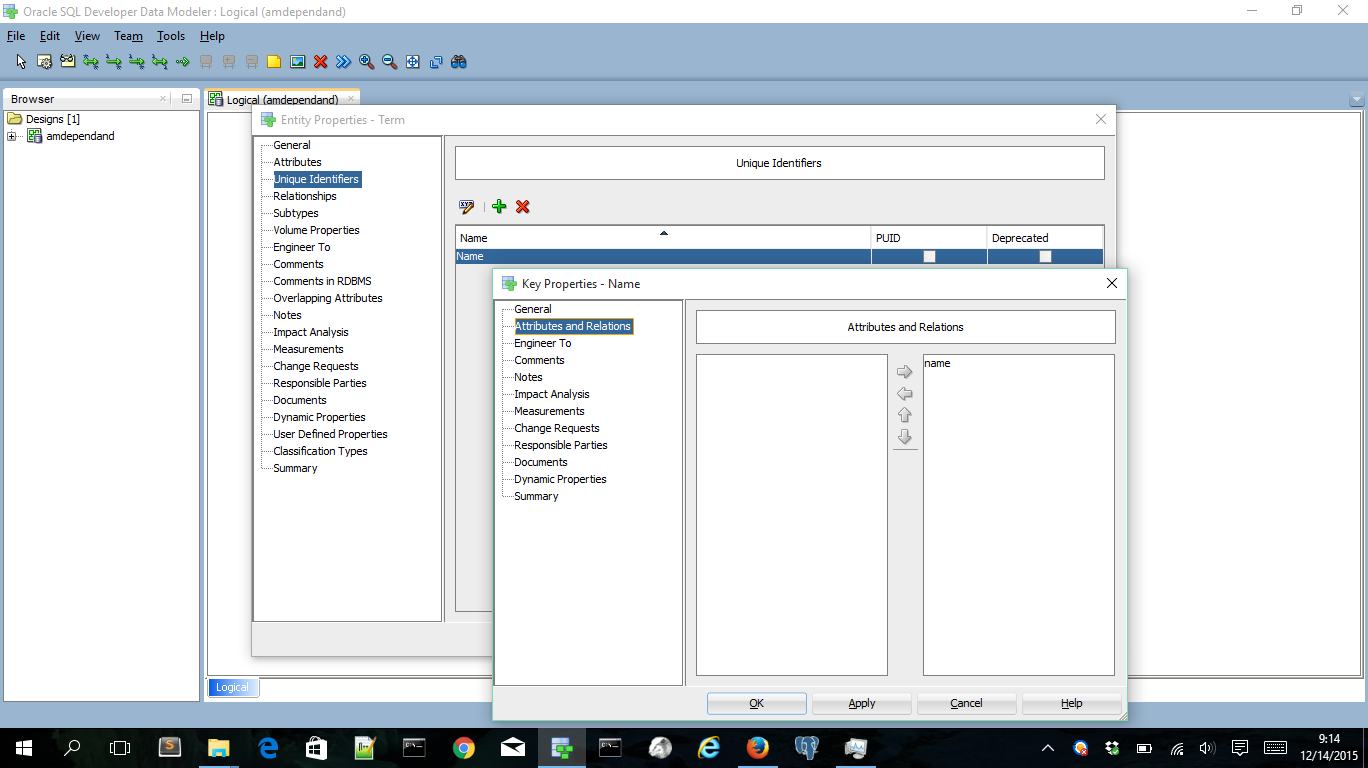
Models have unique names;
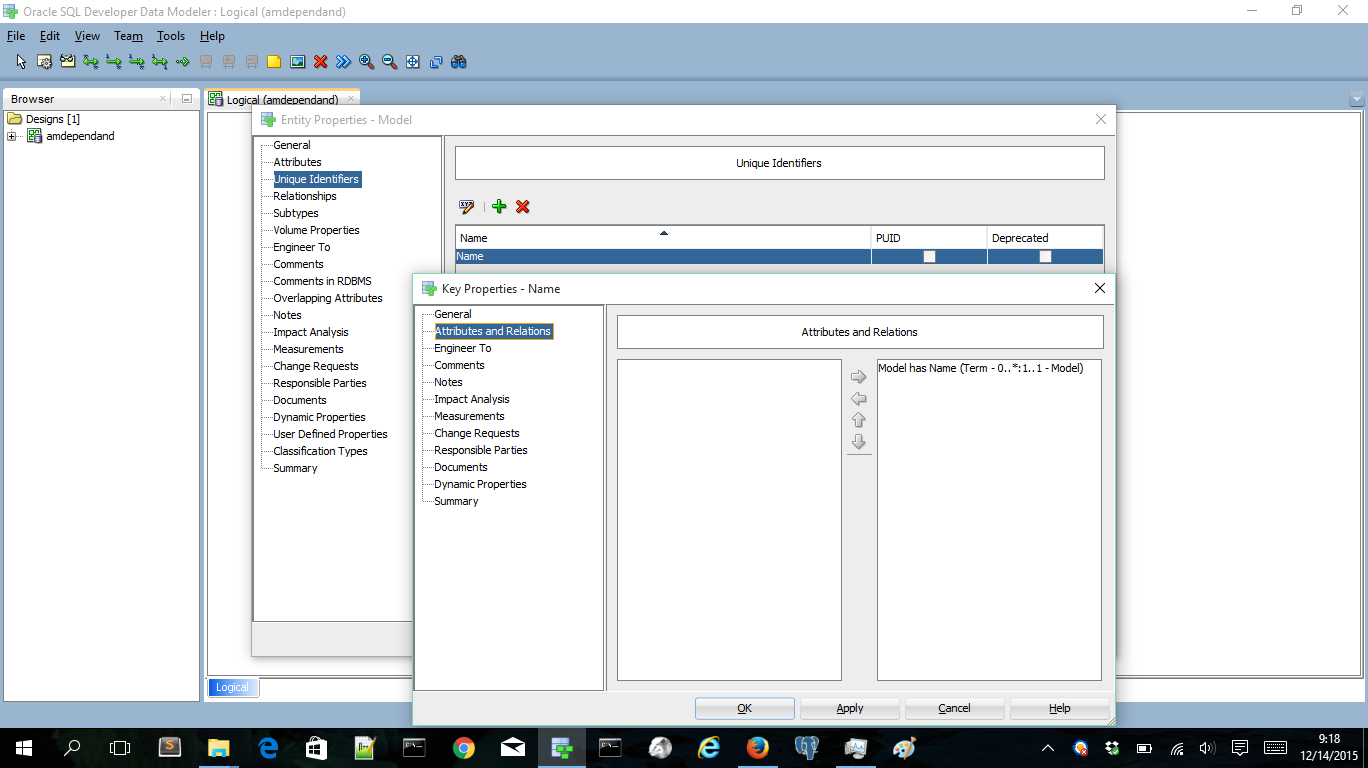
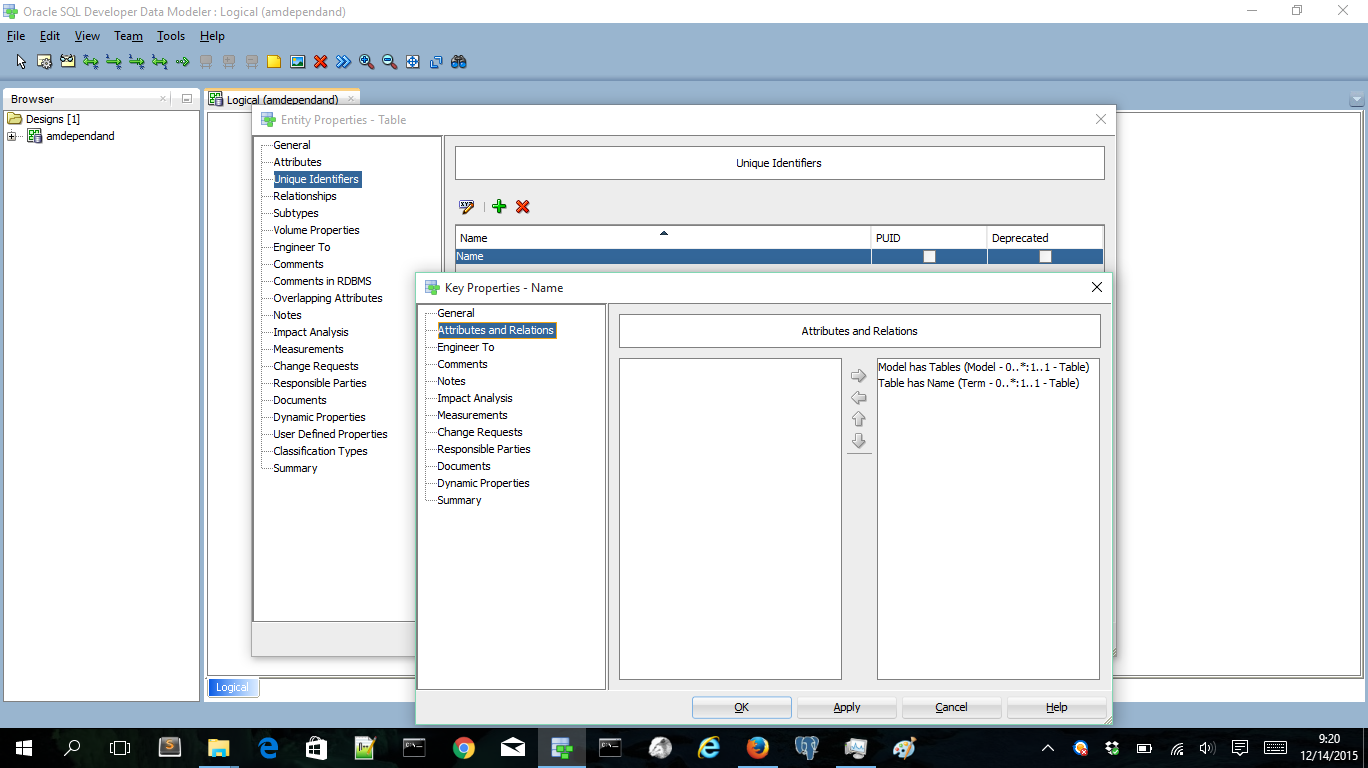
and a Table name is unique within the Model.
This then results in the following logical model:
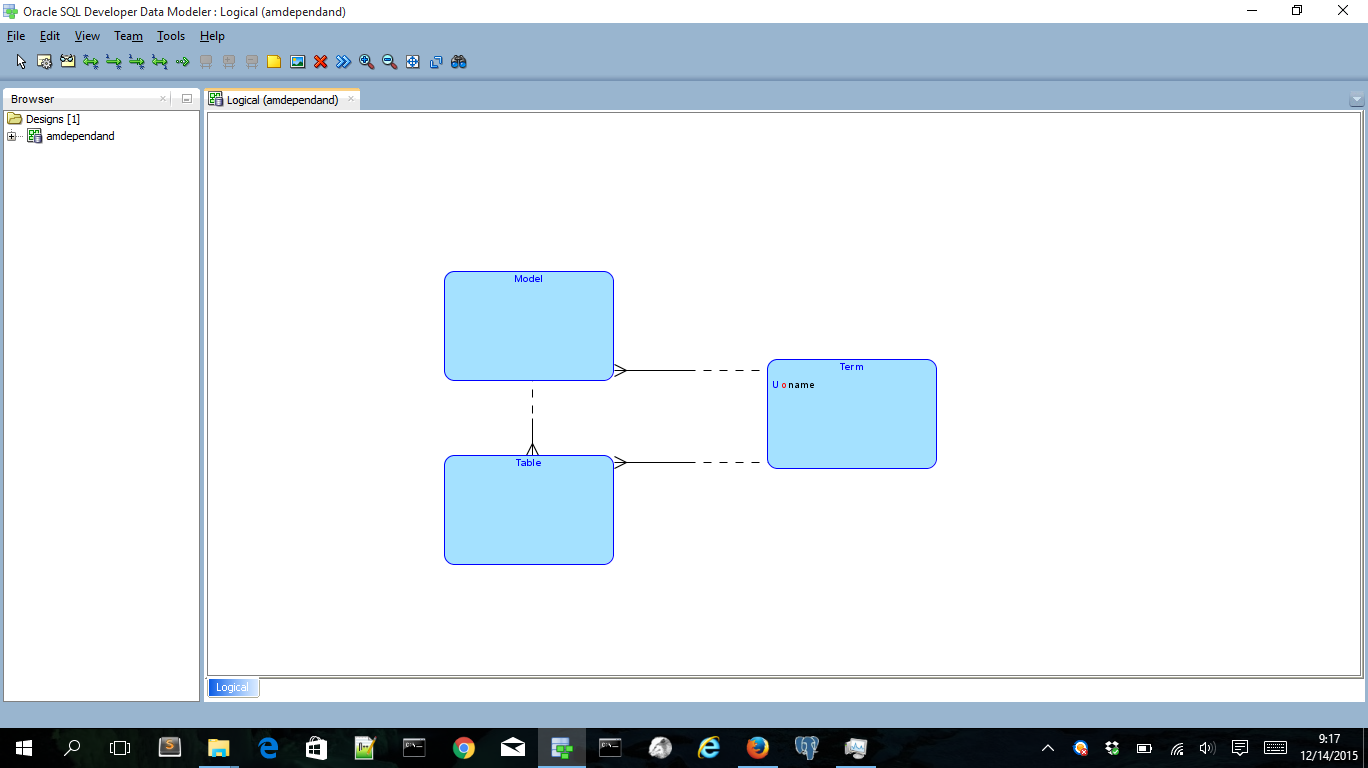
Now we have a small logical model to start with. The logical model I use, is a little UML style. The entities always generate a surrogate key as primary key and the relationships are always on the surrogate keys. First I’m going to generate an ERD relational model from the logical model. This is how we normally would generate a relational model. The next step is to generate an Anchor model by generating again the relational model and then split of tables like I did in previous posts. As a benefit we have mappings from the ERD model to the Anchor model via the logical model. Maybe we can use this in an other post to create the logic to load data in the Anchor model.
OK, let’s generate the ERD model and see how it looks.
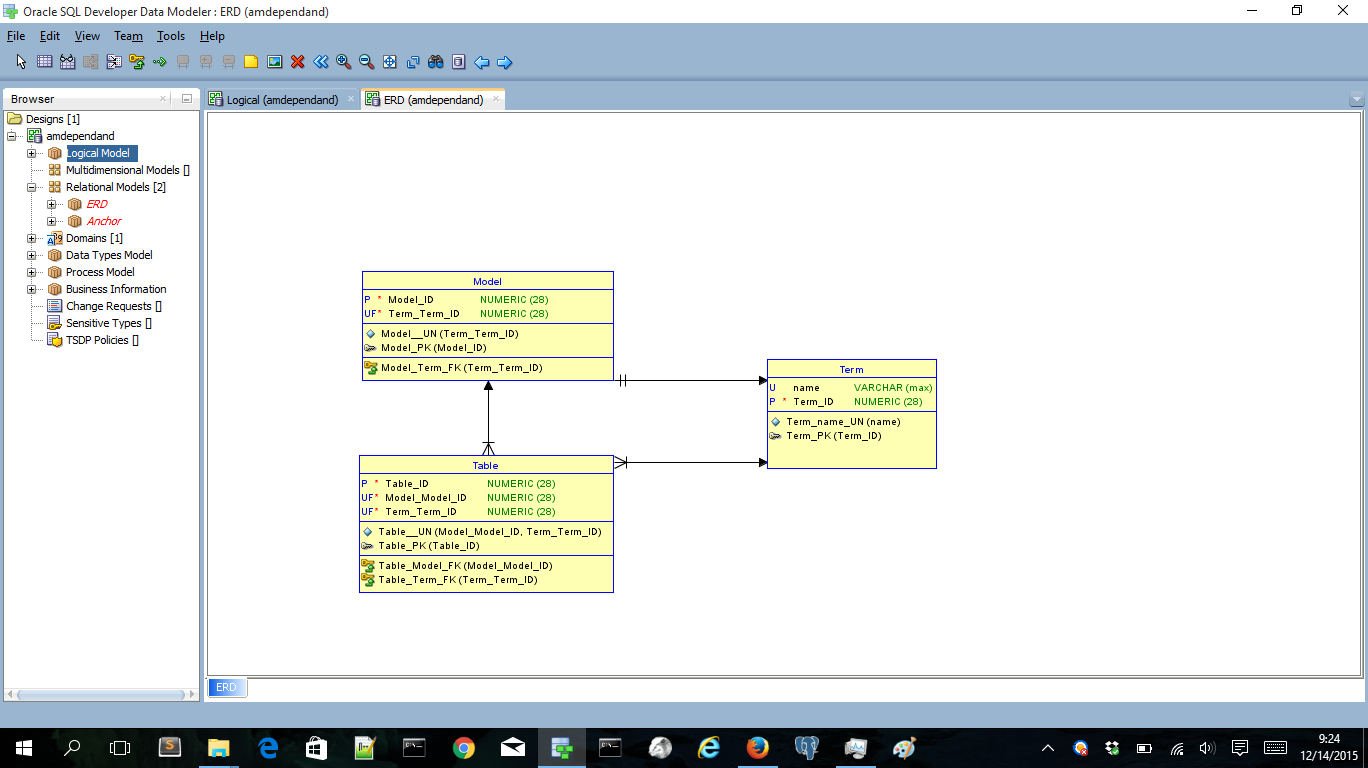
Looks fine to me. The three entities are converted to tables. All surrogate and unique keys are correctly generated and all relationships are based on the surrogate keys. I’m doing the same trick again to create the second relational model that I’m going to use to create the Anchor model. Then I’m going to split the Model table. The only part we can split of is the FK of Term:
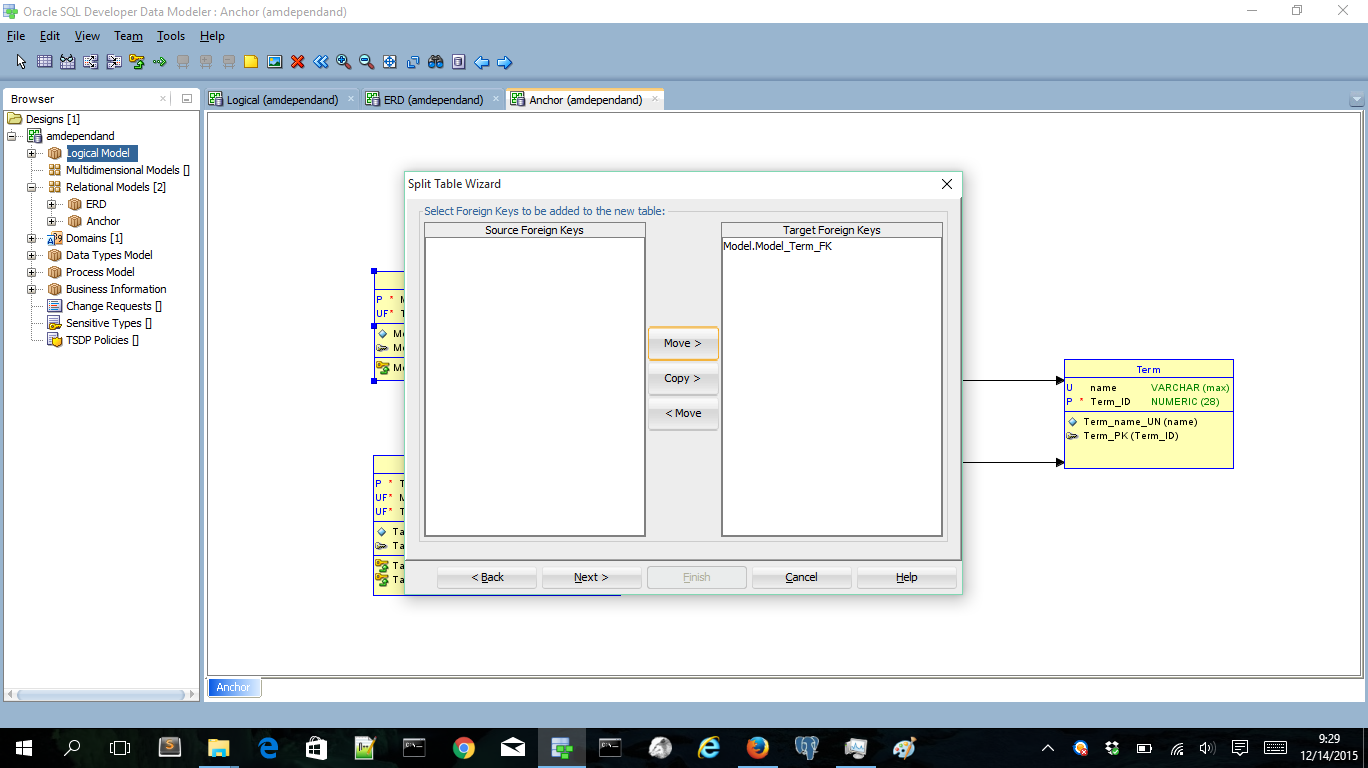
Now we’ve created a 1:1 Tie in Anchor modeling terms:
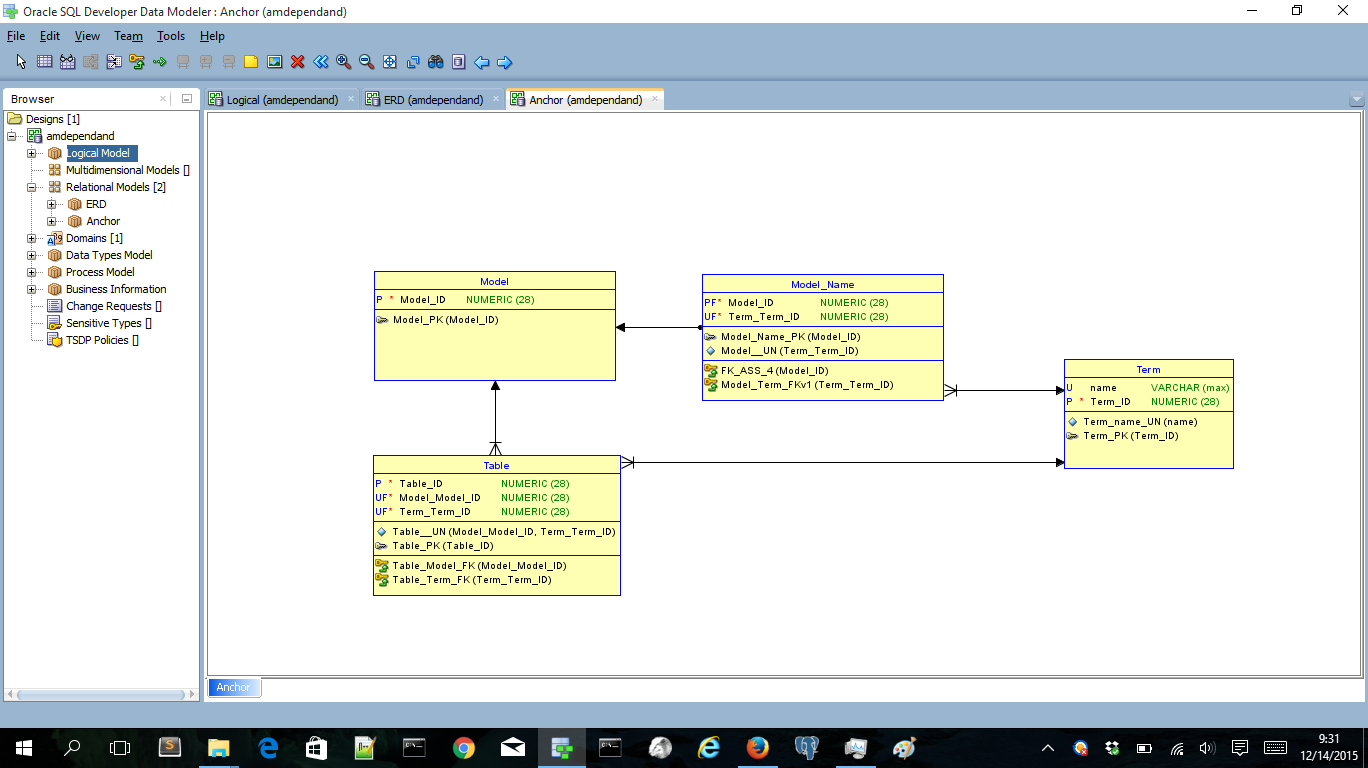
We can do the same with the Table entity. Now we’ll split of the unique identifier of a Table. The unique key is composed of both FK’s. So let’s split of the FK’s:
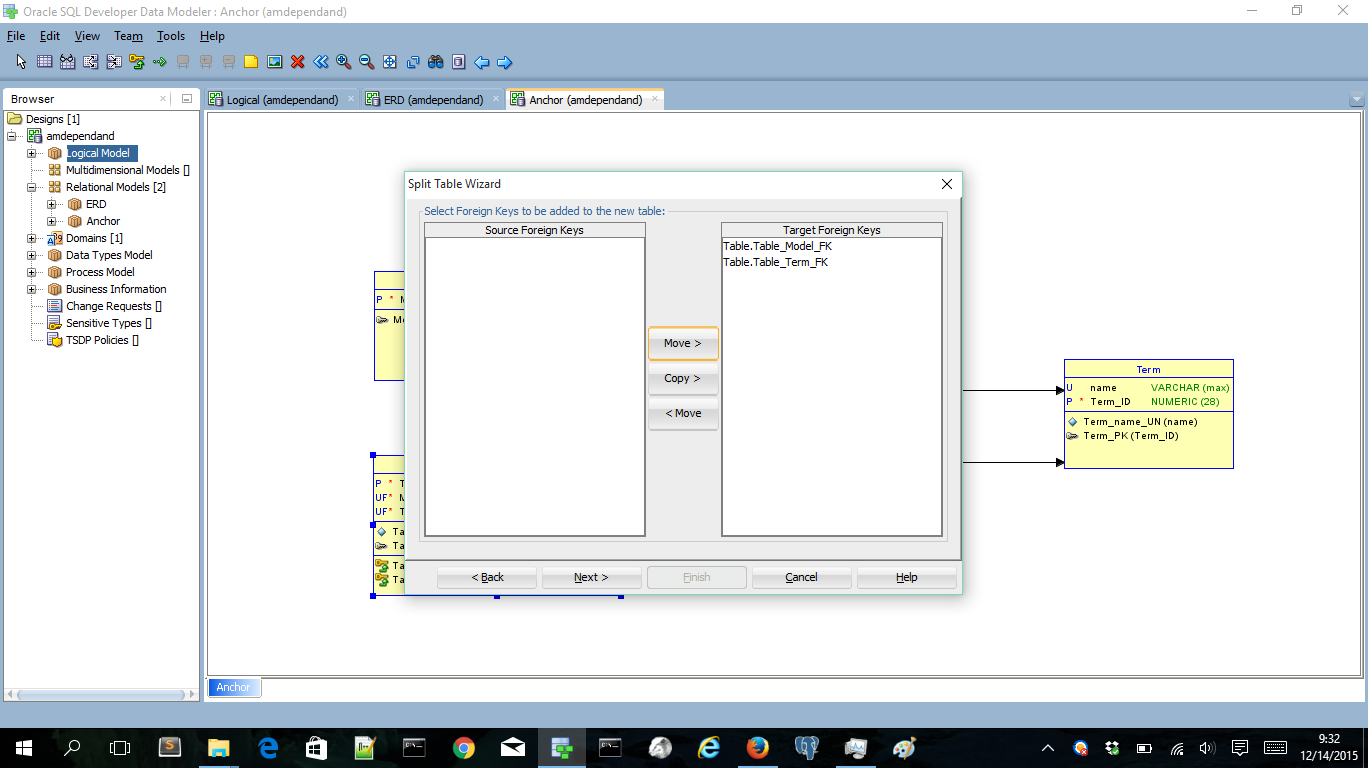
Now we’ve created a three way tie, but with 2 unique keys!
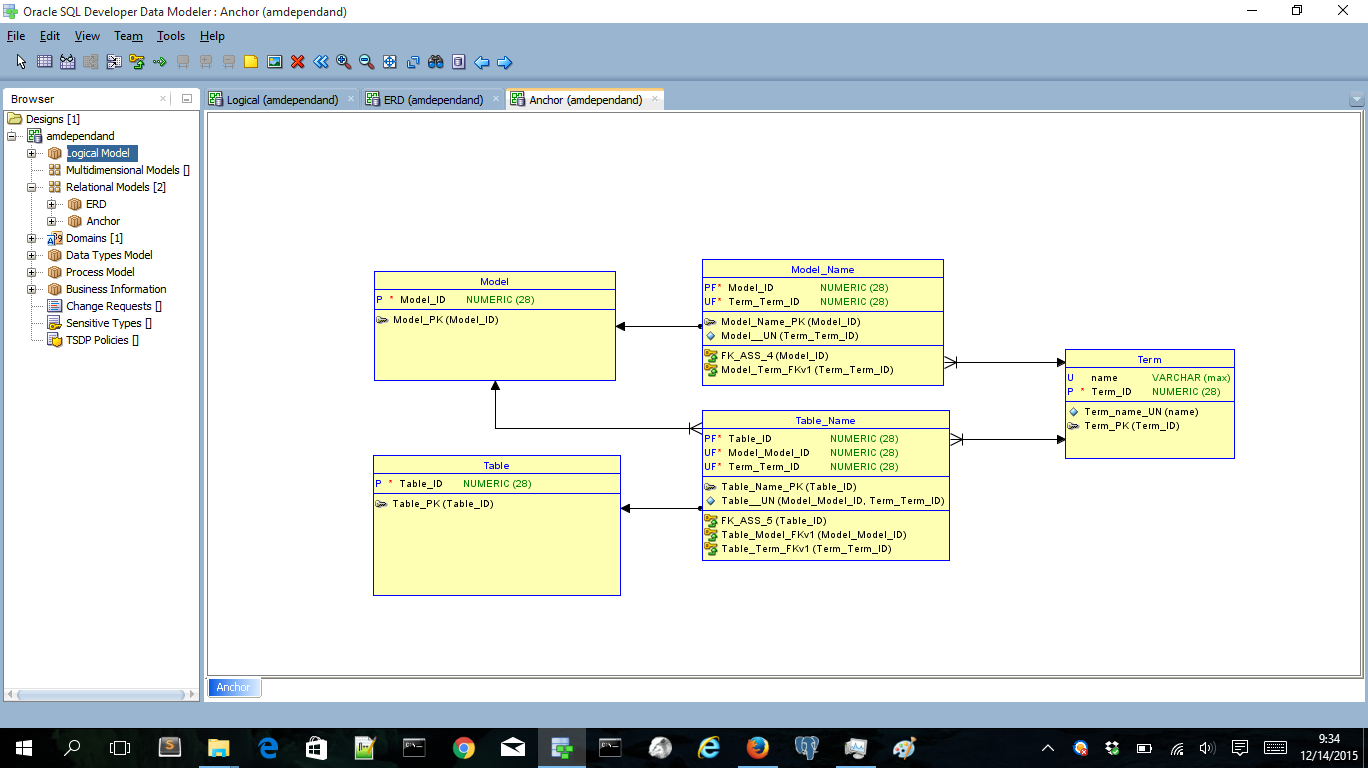
The final step is to split the term table. We’ll split of the name attribute:
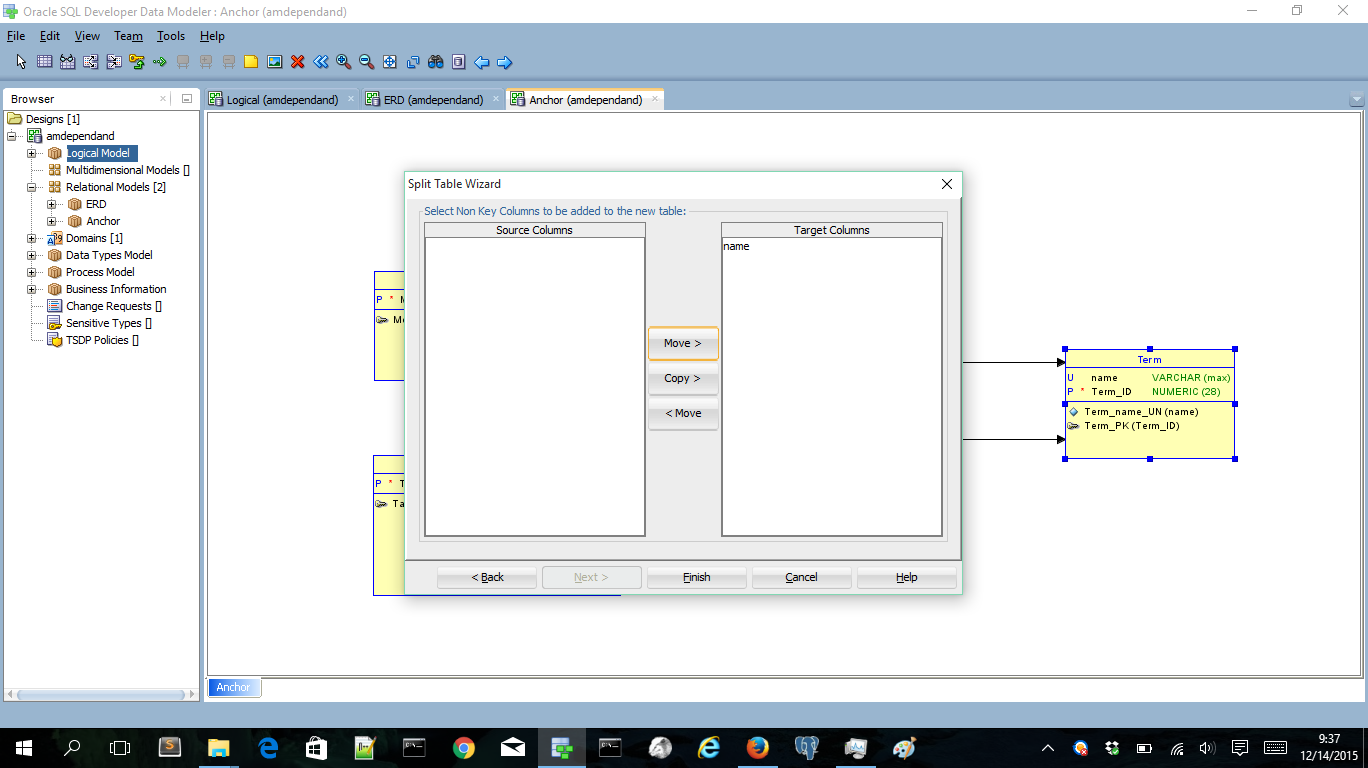
Now we have created an attribute table in Anchor modeling terms. I’m also adding some classifications to get the Anchor modeling coloring style 🙂
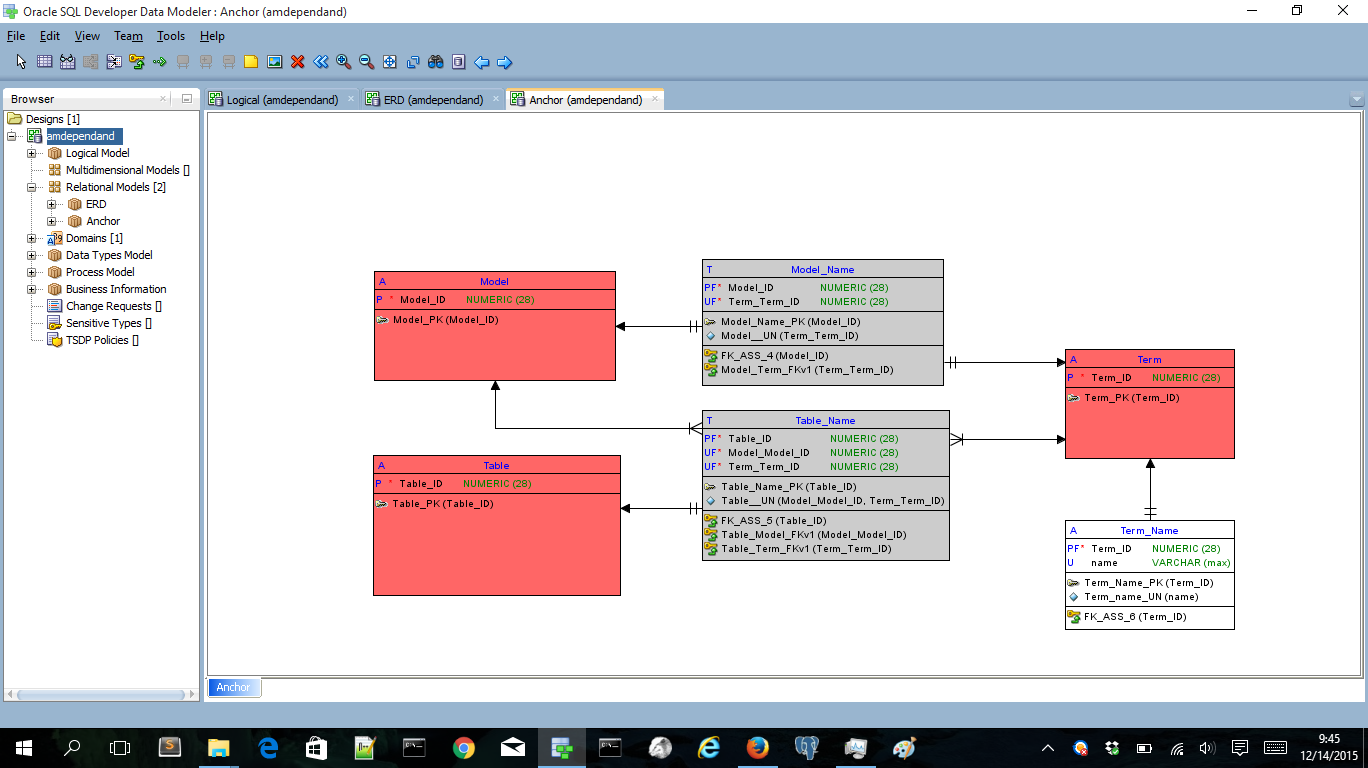
Nice we’ve created an Anchor model out of the original logical model. The (almost) equivalent model created in the very nice Anchor modeling tool (running locally on my PC):
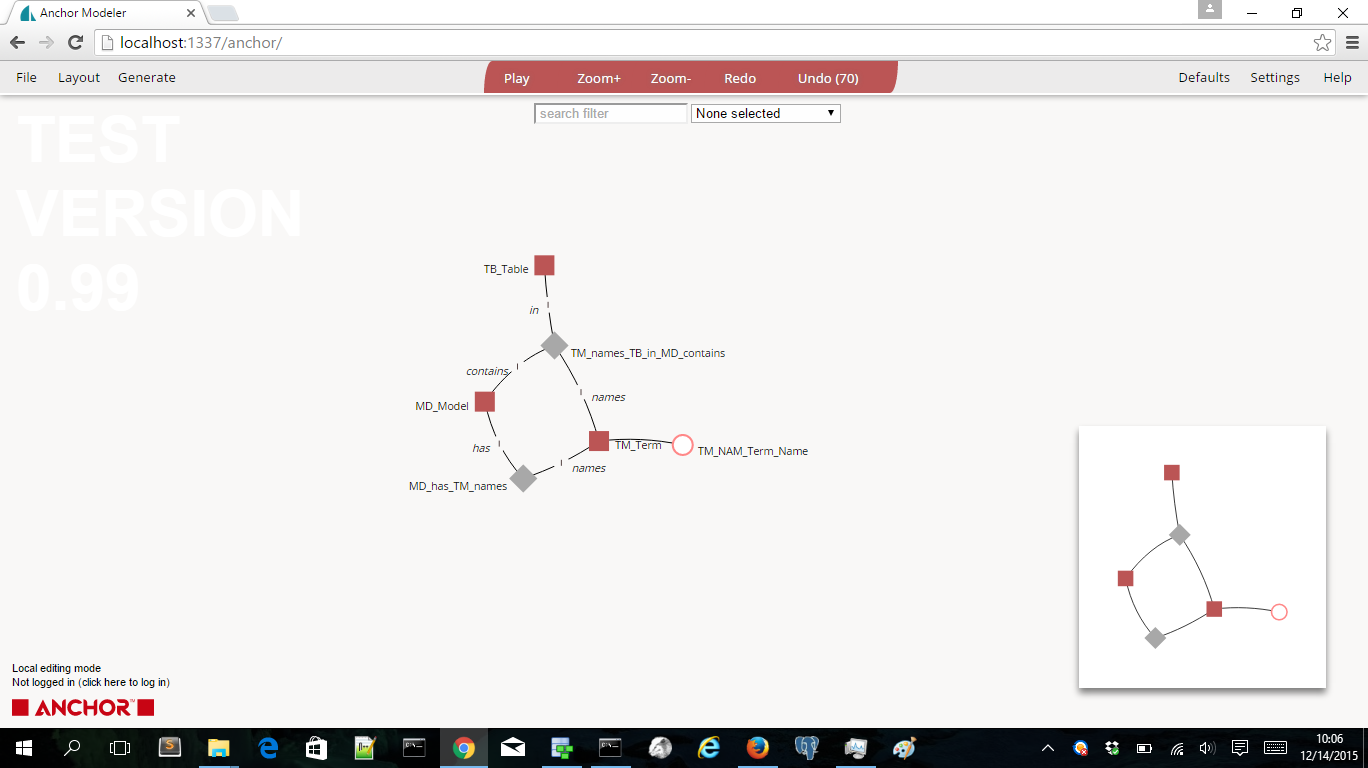
The only thing you have to do is to change is the unique keys of the three way tie. The above model generates three single unique keys in the tie. But we need only two unique keys:
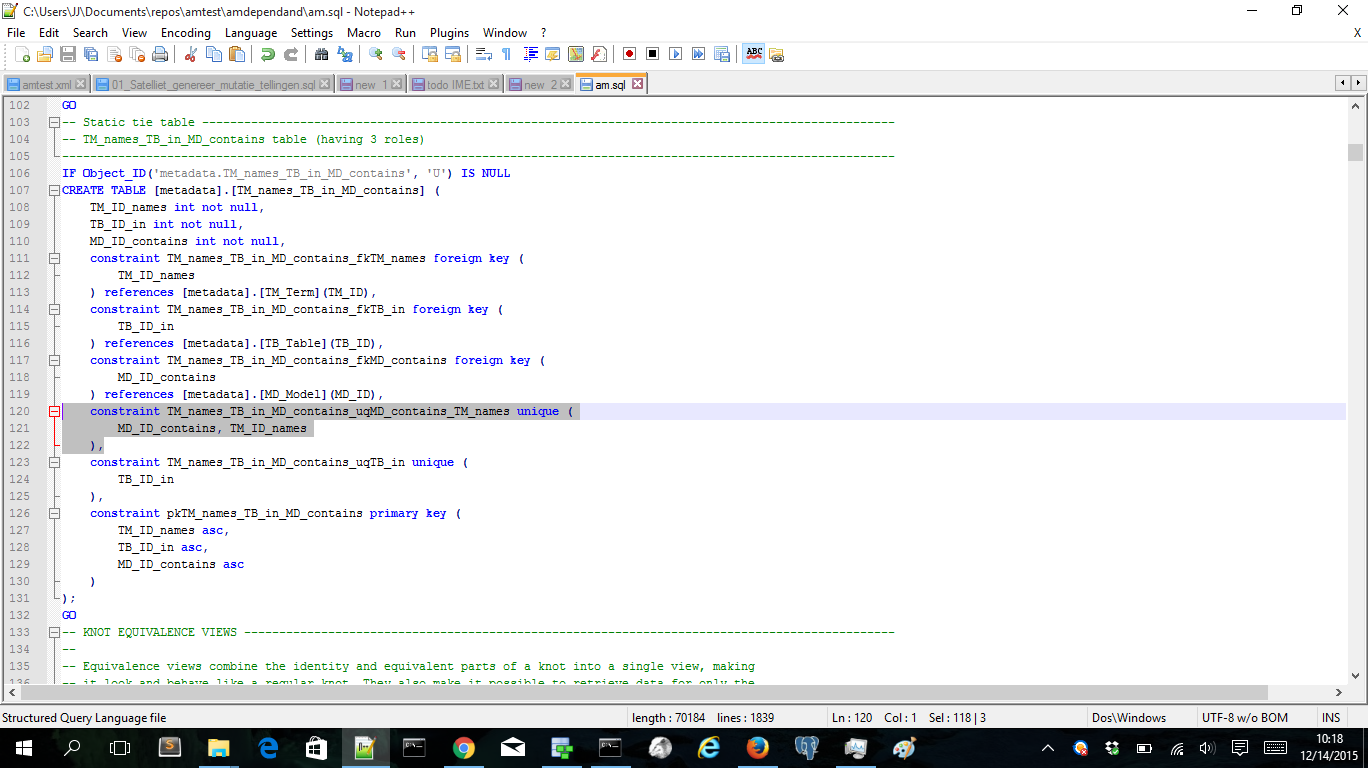
Now we have somehow combined the TM_names and the MD_contains roles. The Anchor modeling tool does a lot more. It also generates views and several table value functions that are acting as parametric views. These let you query easily on the Anchor model 🙂
That’s all for now. I’ve made a GitHub repository with models. Happy Anchor modeling 🙂
















